【每天推薦一篇文章】在計費系統中使用 Event-Driven Architecture 的挑戰
今天終於又鼓起了勇氣來面對堆積如山的收件閘,今天閱讀的是這一篇:
Tackling the challenges of using event-driven architecture in a billing system
在這篇文章裡,作者面對一個牽涉到錢(!)並且非常老舊的系統,使用 Event-driven 來串了一個新服務,並且分享了他們的心得
我覺得有趣的是在於他們遇到的幾個挑戰和做法:
訊息的冪等性
通常我們會希望訊息至少傳遞一次,並且最好只傳遞一次。但有時候還是會因為一些網路因素讓接收方重複收到訊息,這時候作一些處理讓訊息即使重複收到,仍然保持同樣結果就很重要。
這篇文章提出了兩個常見的做法:
Ensuring data consistency through repeated processing: this requires business components to process the same event input and produce the same result.
通過重複處理確保數據一致性:這要求業務組件處理相同的事件輸入並產生相同的結果。
Discarding processed events: after each event is recorded by the system and assigned a unique ID, duplicate events are discarded.
丟棄處理過的事件:系統在每個事件被記錄並分配一個唯一的ID後,會丟棄重複的事件。
印象中之前使用 Azure Service Bus 的時候,就是使用一組 MessageId 來辨別事件
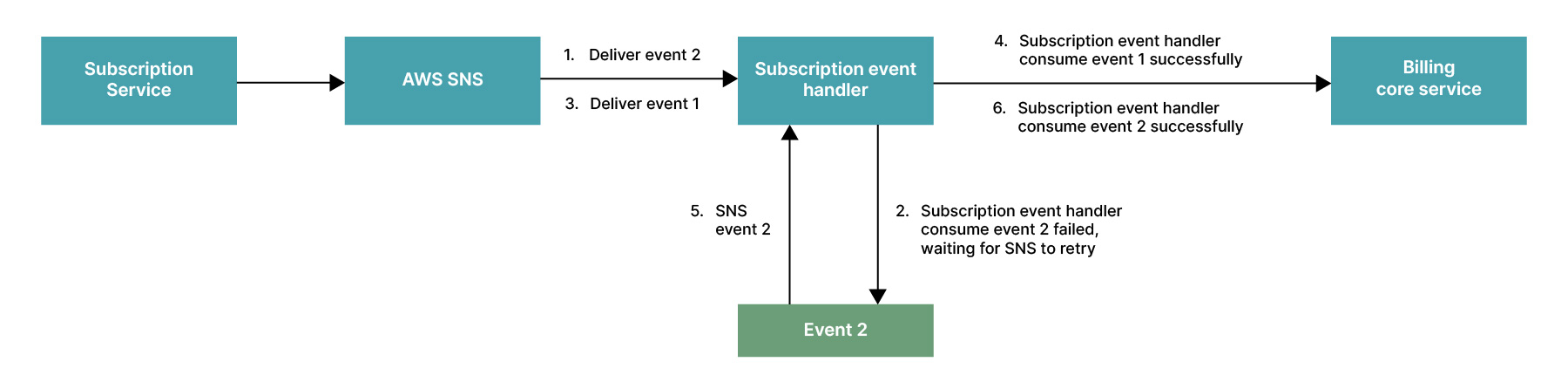
事件處理順序
假設有些事件之間是有順序性的,雖然通常我們會按照時間發送然後接收,但同樣也可能因為網路問題導致順序亂掉。這篇文章則採取以下措施來應對:
In event schema design, we determine the order by designing a version number or ID for the previous order event for the same user’s event.
在事件模式設計中,我們通過為同一使用者的事件設計一個先前訂單事件的版本號或 ID 來確定順序
Ensure events always follow the order of consumption, discard disordered events and wait for the arrival of events that match the order.
確保事件始終按照消費的順序進行,丟棄無序的事件並等待符合順序的事件的到來
處理延遲事件
這項感覺和業務需求比較有關係。主要是 Queue 的延遲性,我們可能在 23:55 發送某個事件,然後 00:05 才被訂閱者收出來處理掉,像這篇需要計算金額的服務就會出問題
這篇的做法就是直接往後抓緩衝,例如在凌晨三點的時候去把前一天的做掉,這三個小時其實就足夠讓前一天的事件內容送達了
不過看這一段的時候有在想,如果真的有事件排隊排到超過這段可容忍的時間,應該需要發送一些警告通知來讓維運人員能夠及時察覺異常會更好?
重新發送事件
簡單來說就是如果接收者掛掉了沒有正確處理事件,發送者要可以重新把事件噴過去。他們除了在重新發送的時候使用 Lambda service 並且控制並發數量來確保性能不要炸裂以外,這邊還額外替事件做了個標記:
Because not all consumers need to consume republished events we can leverage the attribute feature of AWS SNS to add a replay attribute to republished events. Consumers can choose whether or not to subscribe to consume these events based on their needs.
因為並非所有消費者都需要消費重新發布的事件,我們可以利用 AWS SNS 的屬性功能,將重新發布的事件添加一個重播屬性。消費者可以根據自己的需求選擇是否訂閱並消費這些事件。
文章最後還列了一些他們應用 Event-Driven Architecture 的優缺點,例如可以根據時間段和事件抓出相關的資訊,但也提升了複雜度等等
有興趣的朋友可以再點進去閱讀~
那麼,今天的轉貼就先到這邊。明天見 ><
