Python: 用爬蟲在 PTT 上監聽關鍵字並寄通知信
前陣子很想跟 Netflix 的團購,三不五時就上 PTT 看一下團購板,但看到的時候大多已經截止,還有填單填到一半發現已經收滿的,氣得七竅生煙。故嘗試寫了一個通知,在這邊記錄下來。
目標:當團購板上新發了一篇 Netflix 的文,馬上寄信告訴我。
為了這個目標,我們基本上需要:
- 用爬蟲取得團購板的文章標題
- 能夠寄信(使用 Gmail)
- 持續監視,也就是重複執行
使用 requests 爬蟲
所謂的爬蟲就是傳送 HTTP 去瀏覽網頁,並把網頁的內容(像 HTML 等)打包回來分析使用。
這部分,我是參考這篇 爬蟲極簡教學 來寫的,主要是使用 requests 來取得 HTML,再使用 requests_html 解析,裡面的說明非常詳盡。
除了這兩個,其他常用到的工具還有:解析 HTML 架構的 Beautiful Soup(教學)、模擬瀏覽器的 Selenium 等。一些常用的工具可以參考這篇 爬蟲的工具鍊 的介紹。
接著開始跟隨教學走吧。首先確認目標網站的 HTML,可以發現在 PTT 上每一篇文章都是放在 r-ent 的 div 裡的。
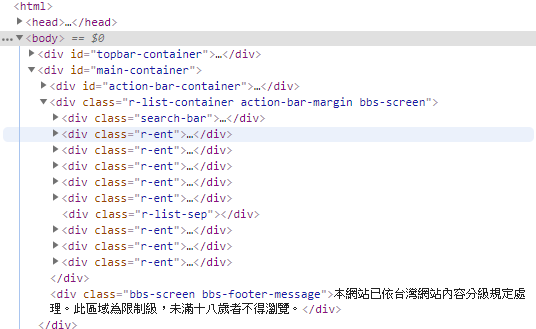
首先就是要先到目標網頁將 HTML 打包回來。此外,PTT 再初次進入時,會跳出視窗詢問是否已經滿十八歲,因此這邊也必須要先處理。
import requests
def fetch(url):
'傳入網址,向 PTT 回答已經滿 18 歲,回傳網頁內容'
response = requests.get(url)
response = requests.get(url, cookies={'over18':'1'})
return response
接下來利用 requests_html 將 div.r-ent 拆出來,也可以用其他的 HTML 解析模組(例如比較熟悉用 Beautiful Soup 之類的時候)來替代:
from requests_html import HTML
def parse_article_entries(doc):
'傳入網頁內容,利用 requests_html 取出 div.r-ent 的元素內容並回傳'
html = HTML( html = doc )
post_entries = html.find('div.r-ent')
return post_entries
最後將拆出來的資料做成字典,方便之後操作。但這邊要注意,被刪除的文章會缺少作者和連結,直接拿會產生錯誤,因此必須要篩掉:
def parse_article_meta(entry):
'將 r-ent 元素的內容格式化成 dict 再回傳'
meta = {
'title': entry.find('div.title', first=True).text,
'push': entry.find('div.nrec', first=True).text,
'date': entry.find('div.date', first=True).text
}
try:
# 正常的文章可以取得作者和連結
meta['author'] = entry.find('div.author', first=True).text
meta['link'] = entry.find('div.title > a', first=True).attrs['href']
except AttributeError:
# 被刪除的文章我們就不要了
meta['author'] = '[Deleted]'
meta['link'] = '[Deleted]'
return meta
到這邊應該能取得首頁上目前的文章了。由於我們做的是監聽團購的目標是不是有人發文,因此我們並不需要再進連結取得內文、或是翻頁繼續爬等更複雜的操作,只需要第一頁的資料就足夠了。(如果想要翻頁,例如說需要爬前一百頁的時候,上面的爬蟲極簡教學有使用抓翻頁按鈕的連結來達成的做法可以參考。)
使用 smtplib 寄信
寄信部分利用 smtplib 來做 SMTP(簡單郵件傳輸)。使用方式相當簡單,可以參考 菜鳥教程的說明 。這邊為了方便,直接使用 Gmail 來寄件。(註:要讓 Gmail 可以用這種程式登入的方法來寄信,需要先開啟允許安全性較低的應用程式設定)
def send_mail_for_me(meta):
'利用 Gmail 的服務寄發通知信'
send_gmail_user = '寄送者@gmail.com'
send_gmail_password = '********'
rece_gmail_user = '接收者@gmail.com'
msg = MIMEText('您所追蹤的 ' + KEYWORD + ' 已經出現在板上!\n 文章:' + meta['title'] + ' \nhttps://www.ptt.cc' + meta['link'])
msg['Subject'] = 'PTT 監聽通知信'
msg['From'] = send_gmail_user
msg['To'] = rece_gmail_user
# 使用 SSL 加密 連線到 gmail 提供的 smtp
server = smtplib.SMTP_SSL('smtp.gmail.com', 465)
server.ehlo()
server.login(send_gmail_user, send_gmail_password)
server.send_message(msg)
server.quit()
這邊目標是將爬到的那一項傳進來寄出去。可以先稍微測試,寄一點垃圾信試試看(找不到的時候記得找一下垃圾信件)。確定收得到之後就可以整合進去了。
本體
接著將上面的兩個部分整合起來:爬蟲,然後如果爬到目標就寄信,沒爬到就準備重爬。這邊先放一個 flog 來準備之後判斷要不要繼續爬的部分。
def ptt_alert(url, keyword):
url = url # 網址
resp = fetch(url) # 取得網頁內容
post_entries = parse_article_entries(resp.text) # 取得各列標題
print('[%s] 連線成功,開始搜尋目標「%s」\n' %(t.now(), KEYWORD))
for entry in post_entries:
meta = parse_article_meta(entry)
# 如果找到關鍵字,而且還沒截止,寄信通知我
# 記得先試著轉小寫,否則大小寫視作不同
if keyword in meta['title'].lower() and not "截止" in meta['title']:
print_meta(meta)
send_mail_for_me(meta)
print('[%s] 已發現監聽目標!通知信已寄出' %t.now())
flog = True # 用來紀錄找到了沒
break
# 沒找到的時候就正常顯示
else:
print_meta(meta)
else:
print('\n[%s] 搜尋完畢,並未發現目標。正在休眠 %s 毫秒並等待下一輪搜尋……' %(t.now(), SLEEPTIME))
接著就是重複執行的部分。抱著嘗試的精神試過 Win內建的工作排程器、apscheduler 等,最後還是簡單最好,用傳統的 while 和 break 解決。另外,這邊用 time.sleep 做延遲,延遲的時間需要自己衡量一下。例如說團購板的發文速度並不算快,五分鐘爬一次已經差不多;但若是發文速度較快的板,則可能需要向 縮短每輪間隔時間 或是 一次爬比較多頁 這兩個方向去做處理。
def main():
try:
while True:
print('[%s] 開始執行監聽' %t.now())
ptt_alert(URL, KEYWORD) # 開始執行
if flog: # 如果執行後有找到目標
print('[%s] 已發現目標,停止監聽' %t.now())
break
else:
time.sleep(SLEEPTIME)
except Exception as e:
print('[%s] 執行期間錯誤:%s' %(t.now(), e))
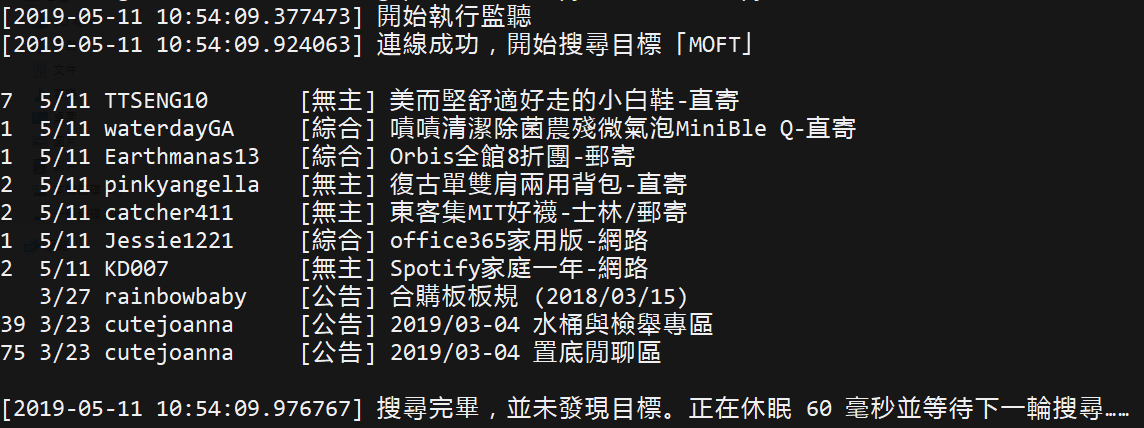
嘗試搜尋看看:
稍微改個關鍵字來測試找到的狀況:
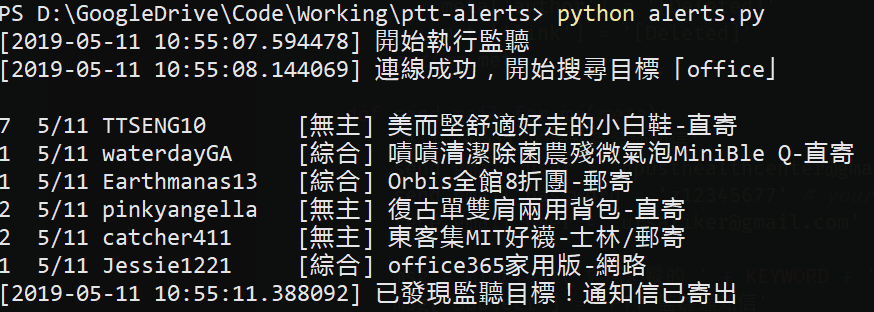
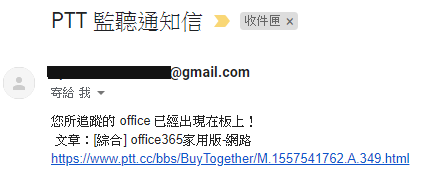
大功告成!
雖然還有一些可以拿來玩的地方,例如說呼叫時能輸入關鍵字,或是連接 Line 機器人做通知等等,但算是大致完工了。下面附上完整程式碼:
# 爬蟲相關套件
import requests
from requests_html import HTML
# 寄信相關套件
import smtplib
from email.mime.text import MIMEText
# 計時器相關套件
import time
import datetime as dt
# ===== 參數 =====
URL = 'https://www.ptt.cc/bbs/BuyTogether/index.html' # 目標看板網址
KEYWORD = 'netflix' # 搜尋關鍵字
SLEEPTIME = 60 # 每輪搜尋休眠時間
# ===== 參數 =====
flog = False # 判斷是否已尋找到目標用的
t = dt.datetime # 顯示時間用的
def fetch(url):
'傳入網址,向 PTT 回答已經滿 18 歲,回傳網頁內容'
response = requests.get(url)
response = requests.get(url, cookies={'over18':'1'})
return response
def parse_article_entries(doc):
'傳入網頁內容,利用 requests_html 取出 div.r-ent 的元素內容並回傳'
html = HTML( html = doc )
post_entries = html.find('div.r-ent')
return post_entries
def parse_article_meta(entry):
'將 r-ent 元素的內容格式化成 dict 再回傳'
meta = {
'title': entry.find('div.title', first=True).text,
'push': entry.find('div.nrec', first=True).text,
'date': entry.find('div.date', first=True).text
}
try:
# 正常的文章可以取得作者和連結
meta['author'] = entry.find('div.author', first=True).text
meta['link'] = entry.find('div.title > a', first=True).attrs['href']
except AttributeError:
# 被刪除的文章我們就不要了
meta['author'] = '[Deleted]'
meta['link'] = '[Deleted]'
return meta
def send_mail_for_me(meta):
'利用 Gmail 的服務寄發通知信'
send_gmail_user = '***@gmail.com'
send_gmail_password = '********'
rece_gmail_user = '*****@gmail.com'
msg = MIMEText('您所追蹤的 ' + KEYWORD + ' 已經出現在板上!\n 文章:' + meta['title'] + ' \nhttps://www.ptt.cc' + meta['link'])
msg['Subject'] = 'PTT 監聽通知信'
msg['From'] = send_gmail_user
msg['To'] = rece_gmail_user
server = smtplib.SMTP_SSL('smtp.gmail.com', 465)
server.ehlo()
server.login(send_gmail_user, send_gmail_password)
server.send_message(msg)
server.quit()
def print_meta(meta):
'列印文章資料,看起來整齊一點'
print('{push:<3s}{date:<5s}{author:<15s}{title:<40s}'\
.format(push = meta['push'], date = meta['date'], author = meta['author'], title = meta['title']))
# 程式本體
def ptt_alert(url, keyword):
url = url # 團購版
resp = fetch(url) # 取得網頁內容
post_entries = parse_article_entries(resp.text) # 取得各列標題
print('[%s] 連線成功,開始搜尋目標「%s」\n' %(t.now(), KEYWORD))
for entry in post_entries:
meta = parse_article_meta(entry)
# 如果找到關鍵字,寄信通知我
if keyword in meta['title'].lower() and not "截止" in meta['title']:
print_meta(meta)
send_mail_for_me(meta)
print('[%s] 已發現監聽目標!通知信已寄出' %t.now())
flog = True
break
# 沒找到的時候就正常顯示
else:
print_meta(meta)
else:
print('\n[%s] 搜尋完畢,並未發現目標。正在休眠 %s 毫秒並等待下一輪搜尋……' %(t.now(), SLEEPTIME))
# 主流程部分
def main():
try:
while True:
print('[%s] 開始執行監聽' %t.now())
ptt_alert(URL, KEYWORD) # 開始執行主流程
if flog:
print('[%s] 已發現目標,停止監聽' %t.now())
break
else:
time.sleep(SLEEPTIME)
except Exception as e:
print('[%s] 執行期間錯誤:%s' %(t.now(), e))
if __name__ == '__main__':
main()
